06 실습 - 상품 연관 검색
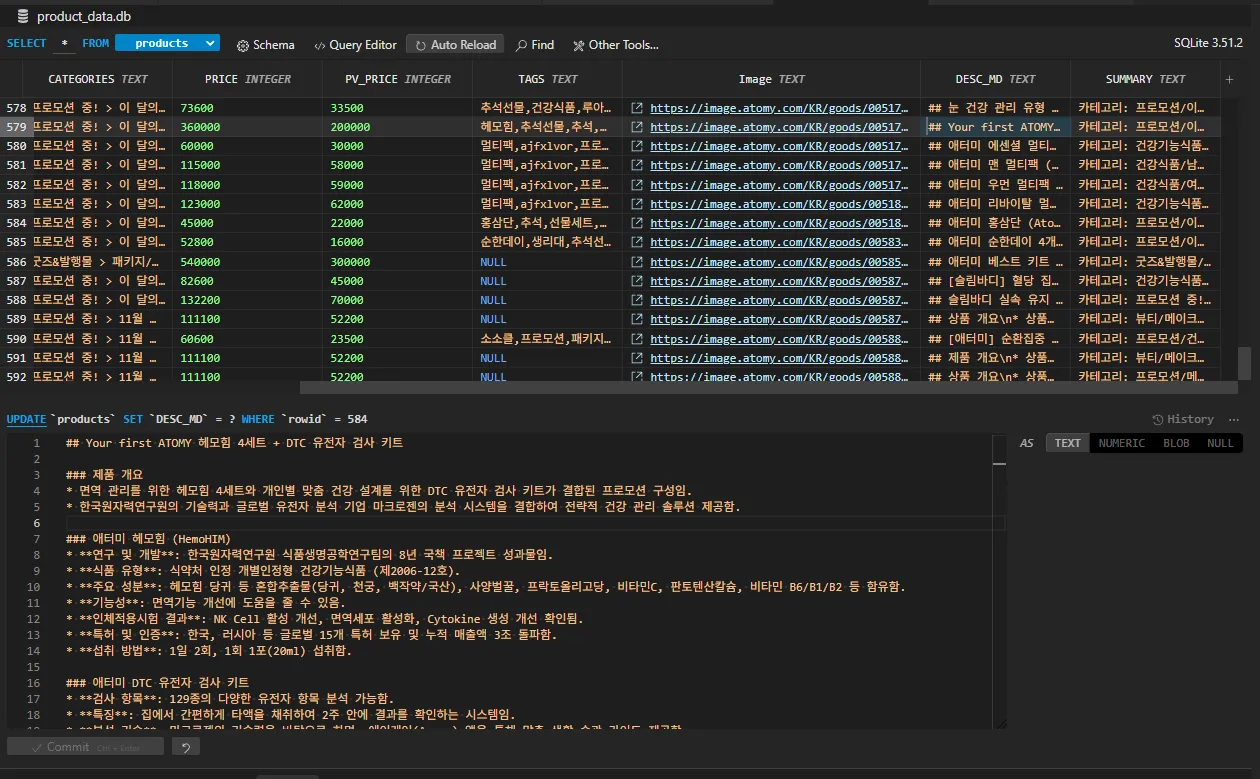
- 한국 상품 정보를 담고 있는 sqlite3 DB(로컬에서 동작되는 가벼운 DB) 파일을 가지고 벡터 검색을 테스트 합니다.
- 해당 테이블에는 상품코드, 가격, 썸네일 이미지정보, 제품 설명이 들어있습니다.(사전 정리된)
사전 준비 사항
Section titled “사전 준비 사항”- product_data.db —> 사전 slack으로 공유
2. Antigravity 실습
Section titled “2. Antigravity 실습”프로그램이 간단하기 때문에 간단한 프롬프트로 프로그램을 생성합니다.
프로그램 생성 프로프트
Section titled “프로그램 생성 프로프트”docs/spec-product-search.md 에 다음을 입력합니다.
# RAG 제품 검색 앱 개발 명세서
## 참고 자료- [벡터 검색 실습](vector-search-app.py)
## 개발 목표- 벡터 임베딩과 시맨틱 검색을 활용한 제품 검색 앱 개발
## 소스 자료- sqlite3 로 된 DB (product_date.db)- product_date.db 의 TABLE 구조```sqlCREATE TABLE `products` ( "PRODUCT_ID" TEXT, -- 상품 코드(0으로 시작하며 숫자가 아닌 문자임) "PRODUCT_NAME" TEXT, -- 상품 이름 "CATEGORIES" TEXT, -- 상품 카테고리 "PRICE" INTEGER, -- 가격 "PV_PRICE" INTEGER, -- PV 값 "TAGS" TEXT, -- 검색 테그 "Image" TEXT, -- 썸네일 이미지 주소 "DESC_MD" TEXT, -- 상세 설명 "SUMMARY" TEXT -- 요약 설명);```
## 개발 사항- chromaDB를 사용해서 벡터 DB를 구축합니다.- chromaDB에 MetaTag로써 PRODUCT_ID, PRODUCT_NAME, CATEGORIES, PRICE, PV_PRICE, TAGS, Image, SUMMARY 를 저장합니다.- chromaDB에 임베딩은 DESC_MD의 데이터로 합니다. 임베딩 모델은 "Alibaba-NLP/gte-multilingual-base"를 사용합니다.(참고 자료)- 프로그램 처음 시작시(chromaDB가 없는 경우에) product_date.db의 데이터를 읽어서 벡터 DB를 구축합니다.(chroma 폴더를 만들어서 해당 폴더안에 저장), 총 상품수가 606개 임으로 배치 사이즈를 30으로 진행- gradio를 이용해서 UI를 만듭니다. 입력 필드로 검색어를 입력받고, 검색 결과를 테이블 형태로 보여줍니다. 검색 결과는 10개까지 보여줍니다. 검색 결과는 해당 metaTag 및 원본데이터(chromaDB의 documents)를 보여줍니다.- UI스타일은 기존 프로젝트와 유사하게 만들어주세요.
## 파일 이름- vector-search-product.py
## chromaDB 사용 및 기타 사용 패키지 설치- 해당 db와 다른 기능을 사용하기 위한 패키지를 설치해주고 해당 정보는 프로그램 상단에 주석으로 정리해주세요.- chromaDB를 사용해서 벡터 DB를 구축합니다. 단, 최신 버전의 안정적인 구동을 위해 chroma_client.get_or_create_collection()을 사용하여 컬렉션을 초기화하고, collection.count()를 확인하여 데이터가 없을 때만 product_data.db에서 데이터를 불러와 임베딩 및 저장을 수행해 주세요. 임베딩을 수행할 때는 한 번에 처리하지 말고, 메모리 오버플로우를 막기 위해 for문으로 제품 데이터를 1개씩 도며 개별 임베딩 생성 후 즉시 ChromaDB에 순차적으로 추가해 주시기 바랍니다. 진행률 피드백도 30개 단위로 콘솔에 나타나게 해주세요.3. 프롬프트에 입력
Section titled “3. 프롬프트에 입력”- Antigravity 프롬프트에 다음과 같이 입력합니다.
- “@spec-product-search.md 를 보고 해당 프로그램을 만들어줘. 필요한 패키지를 자동 설치해줘”
4. 프로그램 실행
Section titled “4. 프로그램 실행”- 프로그램을 처음 실행하면 5분~10분에 걸처 벡터 데이터를 만듭니다.(청킹없이 수행해서 시간이 좀 오래걸림)
User@scchoi MINGW64 /e/ai-test-project/vector-search$ python vector-search-product.py[Alibaba-NLP/gte-multilingual-base] 임베딩 모델을 로드합니다...Some weights of the model checkpoint at Alibaba-NLP/gte-multilingual-base were not used when initializing NewModel: ['classifier.bias', 'classifier.weight']- This IS expected if you are initializing NewModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).- This IS NOT expected if you are initializing NewModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).모델 로드 완료!
ChromaDB 경로: ./chromaChromaDB 컬렉션에 데이터가 없습니다.'product_data.db' 파일에서 데이터를 읽어와 임베딩을 시작합니다.총 606개의 상품 데이터를 처리합니다.진행 상태: 30 / 606 개 완료진행 상태: 60 / 606 개 완료진행 상태: 90 / 606 개 완료진행 상태: 120 / 606 개 완료진행 상태: 150 / 606 개 완료진행 상태: 180 / 606 개 완료진행 상태: 210 / 606 개 완료진행 상태: 240 / 606 개 완료진행 상태: 270 / 606 개 완료진행 상태: 300 / 606 개 완료진행 상태: 330 / 606 개 완료진행 상태: 360 / 606 개 완료진행 상태: 390 / 606 개 완료진행 상태: 420 / 606 개 완료진행 상태: 450 / 606 개 완료진행 상태: 480 / 606 개 완료진행 상태: 510 / 606 개 완료진행 상태: 540 / 606 개 완료진행 상태: 570 / 606 개 완료진행 상태: 600 / 606 개 완료진행 상태: 606 / 606 개 완료벡터 DB 구축 완료! (총 저장된 상품 수: 606)
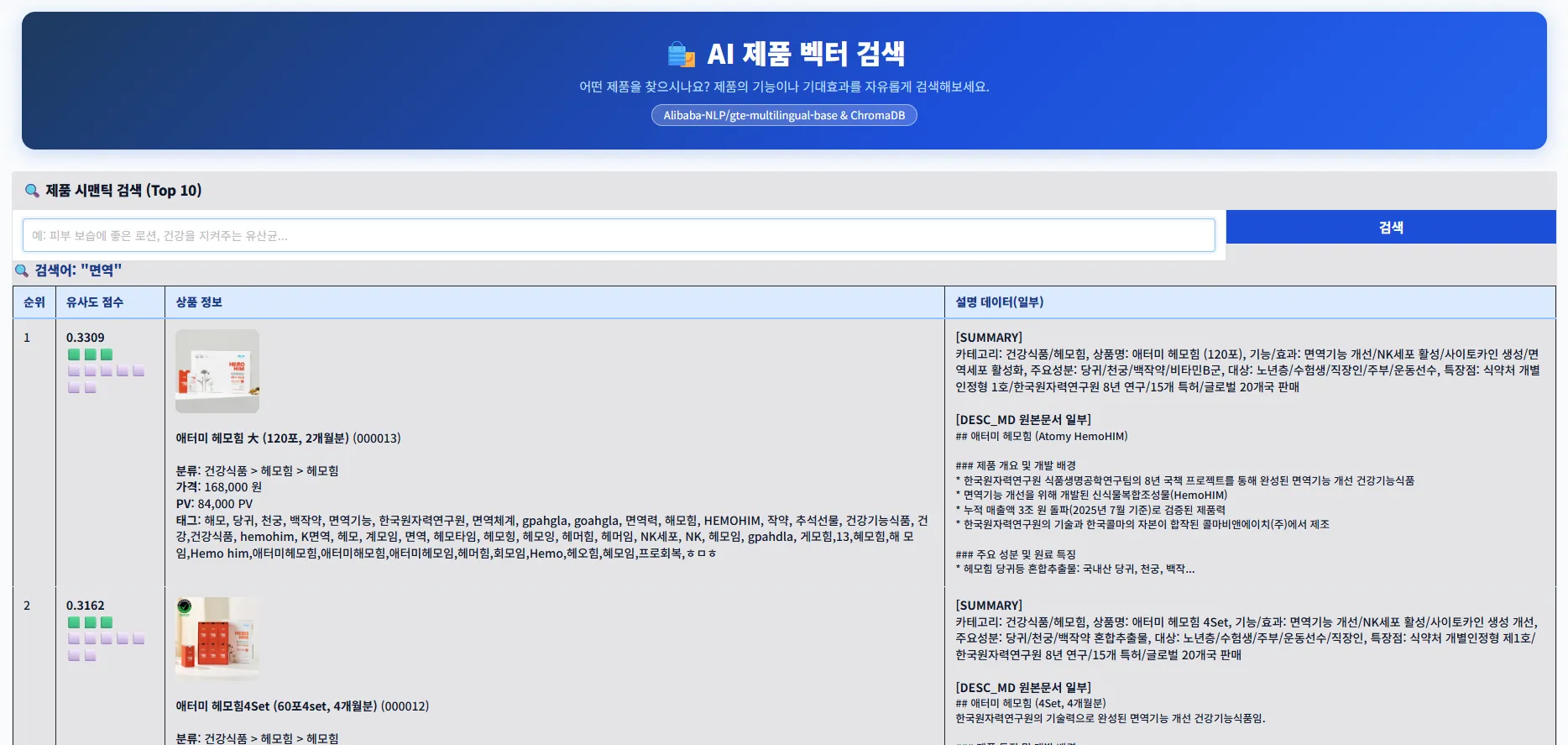
E:\ai-test-project\vector-search\vector-search-product.py:249: UserWarning: The parameters have been moved from the Blocks constructor to the launch() method in Gradio 6.0: css. Please pass these parameters to launch() instead. with gr.Blocks(css=CSS, title="제품 시맨틱 검색") as demo:* Running on local URL: http://127.0.0.1:7860* To create a public link, set `share=True` in `launch()`.5. 실행 화면
Section titled “5. 실행 화면”해당 화면에서 여러 상품과 관련된 단어 및 문장으로 관련 상품 검색이 되는지 확인이 가능합니다.
6. 참고(해당 생성 코드)
Section titled “6. 참고(해당 생성 코드)”# ============================================================# RAG 제품 검색 앱 (Vector Search Product App)## 필요 패키지 설치 방법 (터미널 또는 명령 프롬프트에서 아래 명령어 실행):# pip install chromadb sentence-transformers gradio numpy# ============================================================
import osimport sqlite3import numpy as npimport gradio as grimport chromadbfrom chromadb.config import Settingsfrom sentence_transformers import SentenceTransformer
# ============================================================# 1. 모델 로드# ============================================================MODEL_ID = "Alibaba-NLP/gte-multilingual-base"print(f"[{MODEL_ID}] 모델을 로드합니다...")print("최초 실행 시 모델 다운로드로 인해 수 분이 소요될 수 있습니다.")model = SentenceTransformer(MODEL_ID, trust_remote_code=True)print("모델 로드 완료!\n")
# ============================================================# 2. 벡터 DB(ChromaDB) 초기화# ============================================================CHROMA_DIR = "./chroma"SQLITE_DB = "product_data.db"COLLECTION_NAME = "products"
# ChromaDB 클라이언트 설정 (로컬 파일 시스템에 저장)chroma_client = chromadb.PersistentClient(path=CHROMA_DIR)
def init_db(): """ ChromaDB 컬렉션이 없으면 sqlite에서 데이터를 읽어와서 구성합니다. """ print("⏳ 벡터 DB 컬렉션을 확인합니다...") # get_or_create_collection을 사용하여 컬렉션이 없으면 생성, 있으면 가져옵니다 collection = chroma_client.get_or_create_collection( name=COLLECTION_NAME, metadata={"hnsw:space": "cosine"} )
if collection.count() > 0: print(f"✅ 기존 ChromaDB 벡터 인덱스(데이터 {collection.count()}건)를 로드했습니다.") return collection
print("⏳ 벡터 DB가 비어있어 새로 구축합니다...")
if not os.path.exists(SQLITE_DB): print(f"⚠️ 오류: {SQLITE_DB} 파일을 찾을 수 없습니다. 앱이 정상 작동하지 않을 수 있습니다.") return collection
# SQLite 접근 conn = sqlite3.connect(SQLITE_DB) cursor = conn.cursor() cursor.execute(""" SELECT PRODUCT_ID, PRODUCT_NAME, CATEGORIES, PRICE, PV_PRICE, TAGS, Image, DESC_MD, SUMMARY FROM products """) rows = cursor.fetchall() conn.close()
if not rows: print("⚠️ 데이터베이스에 데이터가 없습니다.") return collection
ids = [] documents = [] metadatas = []
print(f"📦 DB에서 {len(rows)}개의 제품 정보를 바탕으로 임베딩을 준비합니다.")
for row in rows: p_id, p_name, cats, price, pv, tags, img, desc, summary = row product_id_str = str(p_id) if p_id else "unknown_id"
# DESC_MD가 없는 경우 대응 doc = desc if desc else "설명 없음"
ids.append(product_id_str) documents.append(doc)
# ChromaDB 메타데이터에는 None이 포함될 수 없으므로 기본값 처리 metadatas.append({ "PRODUCT_ID": product_id_str, "PRODUCT_NAME": str(p_name) if p_name else "", "CATEGORIES": str(cats) if cats else "", "PRICE": int(price) if price else 0, "PV_PRICE": int(pv) if pv else 0, "TAGS": str(tags) if tags else "", "Image": str(img) if img else "", "SUMMARY": str(summary) if summary else "" })
print(f"🚀 임베딩 생성 및 ChromaDB 저장을 1개씩 순차적으로 시작합니다...")
for i in range(len(ids)): # 1개씩 임베딩 생성 emb = model.encode([documents[i]], show_progress_bar=False).tolist()
# 1개씩 ChromaDB에 추가 (append) collection.add( ids=[ids[i]], embeddings=emb, documents=[documents[i]], metadatas=[metadatas[i]] ) # 30개 단위로 진행 상황 출력 if (i + 1) % 30 == 0 or (i + 1) == len(ids): print(f"✅ 데이터 처리 중... {i + 1}/{len(ids)} 완료")
print("🎉 벡터 DB(ChromaDB) 구축을 성공적으로 완료했습니다!\n") return collection
# 글로벌 collection 인스턴스 준비collection = init_db()
# ============================================================# 3. 제품 검색 메인 로직# ============================================================def search_products(query: str): if not query.strip(): return "🔍 검색어를 입력하세요.", ""
# 사용자의 검색어를 벡터로 변환 (shape: 1 x 768) query_vec = model.encode([query], show_progress_bar=False).tolist()
# ChromaDB 내에서 코사인 유사도 기반 검색 수행 (Top 10) results = collection.query( query_embeddings=query_vec, n_results=10, include=['documents', 'metadatas', 'distances'] )
# 검색된 결과가 없을 시 if not results['ids'] or len(results['ids'][0]) == 0: return "⚠️ 검색 결과가 없습니다.", ""
distances = results['distances'][0] metadatas = results['metadatas'][0] documents = results['documents'][0]
# 결과 마크다운 생성 rows = [ f"### 🔍 검색어: \"{query}\"", "", "| 순위 | 유사도 점수 | 상품 정보 | 설명 데이터(일부) |", "|:---:|:---:|---|---|", ]
for rank, (dist, meta, doc) in enumerate(zip(distances, metadatas, documents), 1): # 코사인 공간에서 distance = 1 - cosine_similarity 이므로 다시 유사도로 변환 score = max(0.0, 1.0 - dist)
# 10칸 막대 그래픽 filled = int(round(score * 10)) bar = "🟩" * filled + "⬜" * (10 - filled)
# 이미지 태그 처리 (온라인 이미지 URL 가정) img_url = meta.get('Image', '') img_tag = f"<img src='{img_url}' width='100' style='border-radius: 8px;'/>" if img_url else "-"
# 좌측: 상품 메타 정보 prod_id = meta.get('PRODUCT_ID', '') info_block = f"{img_tag}<br/>" info_block += f"**{meta.get('PRODUCT_NAME', '-')}** ({prod_id})<br/><br/>" info_block += f"**분류**: {meta.get('CATEGORIES', '-')}<br/>" info_block += f"**가격**: {meta.get('PRICE', 0):,} 원<br/>" info_block += f"**PV**: {meta.get('PV_PRICE', 0):,} PV<br/>" info_block += f"**태그**: {meta.get('TAGS', '-')}"
# 우측: 원본 텍스트 데이터 (문서 및 요약본) summary = meta.get('SUMMARY', '') # 원본 문서 일부 길이 제한 (지나치게 길 경우 표가 깨지므로 앞부분만 표시) desc_preview = doc.replace('\n', '<br>') if len(desc_preview) > 300: desc_preview = desc_preview[:300] + "..."
text_block = f"**[SUMMARY]**<br/>{summary}<br/><br/>**[DESC_MD 원본문서 일부]**<br/><div style='font-size:0.9em;color:#4b5563;line-height:1.4'>{desc_preview}</div>"
rows.append(f"| {rank} | **{score:.4f}**<br/>{bar} | {info_block} | {text_block} |")
return "\n".join(rows), ""
# ============================================================# 4. Gradio UI (기존 프로젝트 스타일 차용)# ============================================================CSS = """body, .gradio-container { font-family: 'Noto Sans KR', 'Pretendard', sans-serif !important; background-color: #f8fafc !important; color: #111827 !important;}.gradio-container p, .gradio-container span, .gradio-container label, .gradio-container div, .gradio-container td, .gradio-container li { color: #111827 !important;}#app-header { background: linear-gradient(135deg, #1e3a5f 0%, #1d4ed8 60%, #2563eb 100%); border-radius: 16px; padding: 28px 36px; margin-bottom: 8px; text-align: center; box-shadow: 0 4px 20px rgba(37,99,235,0.25);}#app-header h1 { color: #ffffff !important; font-size: 2rem; font-weight: 800; margin: 0 0 6px 0; }#app-header p { color: #bfdbfe !important; font-size: 0.95rem; margin: 0; }#model-badge { display: inline-block; background: rgba(255,255,255,0.2); border: 1px solid rgba(255,255,255,0.5); color: #ffffff !important; border-radius: 20px; padding: 3px 14px; font-size: 0.8rem; margin-top: 10px;}.section-card { background: #ffffff; border: 1px solid #e2e8f0; border-radius: 12px; padding: 20px; box-shadow: 0 1px 6px rgba(0,0,0,0.07);}.section-title { color: #1e3a8a !important; font-size: 1.05rem; font-weight: 800; margin-bottom: 12px; letter-spacing: -0.3px;}.prose * { color: #111827 !important; }.prose h3 { color: #1e3a8a !important; font-weight: 800; }.prose table { width: 100%; border-collapse: collapse; }.prose table th { background: #dbeafe; color: #1e3a8a !important; padding: 9px 12px; border-bottom: 2px solid #93c5fd; font-weight: 800; white-space: nowrap; }.prose table td { padding: 12px 12px; border-bottom: 1px solid #e2e8f0; color: #111827 !important; font-weight: 500; vertical-align: top; }.prose table tr:hover td { background: #eff6ff; }button.primary, .gradio-container button[class*="primary"] { background: #1d4ed8 !important; border-color: #1d4ed8 !important; color: #ffffff !important;}button.primary:hover, .gradio-container button[class*="primary"]:hover { background: #1e40af !important; border-color: #1e40af !important;}"""
with gr.Blocks(css=CSS, title="제품 의미 검색") as demo: # 헤더 gr.HTML(""" <div id="app-header"> <h1>🛍️ AI 제품 벡터 검색</h1> <p>어떤 제품을 찾으시나요? 제품의 기능이나 기대효과를 자유롭게 검색해보세요.</p> <span id="model-badge">Alibaba-NLP/gte-multilingual-base & ChromaDB</span> </div> """)
# 본문 영역 with gr.Row(): with gr.Column(): with gr.Group(elem_classes=["section-card"]): gr.HTML('<div class="section-title">🔍 제품 시맨틱 검색 (Top 10)</div>') with gr.Row(): search_input = gr.Textbox( placeholder="예: 피부 보습에 좋은 로션, 건강을 지켜주는 유산균...", label="검색어", scale=4, show_label=False, ) search_btn = gr.Button("검색", variant="primary", scale=1)
# 검색 결과를 렌더링할 마크다운 영역 search_result_md = gr.Markdown( value="위 검색창에 찾고 싶은 상품이나 관련 설명을 입력하세요.", elem_classes=["prose"], )
# 이벤트 매핑 search_btn.click( fn=search_products, inputs=[search_input], outputs=[search_result_md, search_input] )
search_input.submit( fn=search_products, inputs=[search_input], outputs=[search_result_md, search_input] )
if __name__ == "__main__": demo.launch(inbrowser=True)