03 벡터 검색 실습 세팅
벡터 검색 테스트
Section titled “벡터 검색 테스트”이제 실제로 어떻게 임베딩이 이루어 지는지 간단하게 테스트 하도록 하겠습니다.
1. 패키지 설치 및 프로그램 추가
Section titled “1. 패키지 설치 및 프로그램 추가”패키지 설치
Section titled “패키지 설치”사전 준비사항에서 만든 프로젝트의 터미널에서 다음을 수행합니다.(앞에 설치된 패키지는 skip됩니다.)
D:\vector-search>pip install sentence-transformers scikit-learn gradio프로그램 추가
Section titled “프로그램 추가”vector-search-app.py 라는 파일을 추가하고 다음 내용을 복사/붙여넣기 합니다.
# ============================================================# 벡터 검색 실습 앱 (Vector Search Practice App)## 사용 모델: Alibaba-NLP/gte-multilingual-base# - 다국어(한국어 포함) 텍스트를 고차원 벡터로 변환하는 임베딩 모델# - 최대 입력 토큰: 8192 / 임베딩 차원: 768## 핵심 개념:# 1. 임베딩(Embedding): 텍스트 → 숫자 벡터로 변환# 2. 코사인 유사도(Cosine Similarity): 두 벡터 간 각도로 의미적 유사도 측정# 3. 시맨틱 검색(Semantic Search): 단순 키워드가 아닌 '의미' 기반으로 검색# 그라디오# 사전 설치:# pip install sentence-transformers scikit-learn gradio# ============================================================
import numpy as npimport gradio as grfrom sentence_transformers import SentenceTransformerfrom sklearn.metrics.pairwise import cosine_similarity
# ============================================================# 1. 모델 로드# ============================================================# SentenceTransformer: 문장(sentence) 수준의 임베딩을 생성하는 라이브러리.# 내부적으로 BERT 계열 트랜스포머 모델을 사용하여# 입력 텍스트 전체를 하나의 고정 크기 벡터(여기서는 768차원)로 압축한다.## trust_remote_code=True:# 허깅페이스 허브에 올라온 모델 중 일부는 커스텀 Python 코드를 포함한다.# gte-multilingual-base 도 자체 풀링 로직이 있어 이 옵션이 필요하다.# (최초 실행 시 모델 파일을 허깅페이스 캐시 폴더에 자동 다운로드)MODEL_ID = "Alibaba-NLP/gte-multilingual-base"print(f"[{MODEL_ID}] 모델을 로드합니다...")print("최초 실행 시 모델 다운로드로 인해 수 분이 소요될 수 있습니다.")model = SentenceTransformer(MODEL_ID, trust_remote_code=True)print("모델 로드 완료!\n")
# ============================================================# 2. 사전 정의된 테스트 문장 10개# ============================================================# 의도적으로 아래 3가지 유형을 섞어 임베딩 유사도를 체감할 수 있게 구성:# A) 같은 의미 / 다른 표현 → 유사도 높음# B) 같은 의미 / 다른 언어(한·영) → 다국어 임베딩 성능 확인# C) 전혀 다른 주제 → 유사도 낮음INITIAL_SENTENCES = [ # ── 날씨 관련 (의미 유사 그룹) ───────────────────────────── "오늘 날씨가 정말 화창하고 좋네요.", # 0: 한국어 기준 문장 "오늘 날씨가 참 맑고 아름답습니다.", # 1: 한국어, 0번과 의미 유사 → 높은 유사도 예상 "The weather is really sunny and nice today.", # 2: 영어, 0번과 동일 의미 → 다국어 임베딩 테스트
# ── AI / 기술 관련 ───────────────────────────────────────── "파이썬으로 인공지능 모델을 테스트하는 방법", # 3: AI 개발 주제 "딥러닝과 머신러닝의 차이점은 무엇인가요?", # 4: 3번과 주제 유사 (AI) "자연어 처리 기술은 텍스트를 벡터로 변환합니다.", # 5: 임베딩 자체 설명 문장 "Natural language processing converts text into vectors.", # 6: 5번 영어 번역
# ── 일상 / 음식 관련 (위 그룹과 전혀 다른 주제) ──────────── "서울의 맛있는 음식점을 추천해 주세요.", # 7: 식당/음식 주제 "강남역 근처 카페에서 커피 한 잔 마시고 싶다.", # 8: 7번과 장소·음료 주제 유사
# ── 벡터 검색 개념 ────────────────────────────────────────── "벡터 유사도 검색은 의미 기반 검색을 가능하게 합니다.", # 9: 이 앱 자체 주제]
# ============================================================# 3. 전역 상태 — 문장 리스트 & 임베딩 행렬# ============================================================# sentences : 현재 등록된 문장들의 리스트 (추가될 때마다 확장)# embeddings: shape = (문장 수 N, 768)# 각 행(row)이 해당 문장의 768차원 임베딩 벡터## 앱 시작 시 초기 10개 문장을 한꺼번에 인코딩해 캐싱해 두므로# 검색 시마다 재계산하지 않아도 돼 속도가 빠르다.sentences: list[str] = list(INITIAL_SENTENCES)embeddings: np.ndarray = model.encode(sentences, show_progress_bar=False)# shape 예시: (10, 768) — 10개 문장, 각 768차원 벡터
# ============================================================# 4. 헬퍼 함수# ============================================================
def get_sentence_list_md() -> str: """ 현재 sentences 리스트를 마크다운 테이블 문자열로 반환한다. Gradio의 gr.Markdown 컴포넌트에 직접 렌더링된다. """ rows = ["| # | 문장 |", "|---|------|"] for i, s in enumerate(sentences, 1): rows.append(f"| {i} | {s} |") return "\n".join(rows)
def search_sentences(query: str, top_k: int = 5): """ [시맨틱 검색 핵심 로직]
1) 사용자가 입력한 query 문장을 임베딩 벡터로 변환 query_vec : shape = (1, 768)
2) 저장된 모든 문장의 임베딩 행렬(embeddings)과 코사인 유사도를 일괄 계산 scores : shape = (N,) — N개 문장 각각의 유사도 점수
3) 유사도 점수를 내림차순으로 정렬 후 Top-K 반환
코사인 유사도 공식: cos(θ) = (A · B) / (||A|| × ||B||) 범위: -1 ~ 1 (실제 NLP에서는 보통 0 ~ 1) 1에 가까울수록 의미가 같고, 0에 가까울수록 관련 없음 """ if not query.strip(): return "🔍 검색어를 입력하세요.", ""
# ── 쿼리 임베딩 ────────────────────────────────────────────── # model.encode()는 문자열 리스트를 받으므로 [query] 형태로 감쌈 # 결과: numpy 배열, shape = (1, 768) query_vec = model.encode([query], show_progress_bar=False)
# ── 코사인 유사도 계산 ──────────────────────────────────────── # cosine_similarity(A, B): A의 각 행과 B의 각 행 간 코사인 유사도 계산 # query_vec : (1, 768) / embeddings : (N, 768) # 결과 shape: (1, N) → [0] 으로 1차원 배열 (N,) 추출 scores = cosine_similarity(query_vec, embeddings)[0]
# ── Top-K 정렬 ─────────────────────────────────────────────── # enumerate(scores): (인덱스, 유사도점수) 튜플 생성 # key=lambda x: x[1]: 점수 기준 정렬 ranked = sorted(enumerate(scores), key=lambda x: x[1], reverse=True)[:top_k]
# ── 결과 마크다운 생성 ──────────────────────────────────────── rows = [ f"### 🔍 검색어: \"{query}\"", "", "| 순위 | 점수 | 시각화 | 문장 |", "|:---:|:---:|:---:|------|", ] for rank, (idx, score) in enumerate(ranked, 1): # 점수를 10칸 막대그래프로 시각화 (0.0~1.0 → 0~10칸) filled = int(round(score * 10)) bar = "🟩" * filled + "⬜" * (10 - filled) rows.append(f"| {rank} | **{score:.4f}** | {bar} | {sentences[idx]} |")
return "\n".join(rows), "" # 두 번째 반환값: 검색창 초기화(빈 문자열)
def add_sentence(new_sentence: str): """ [문장 추가 & 실시간 임베딩]
새 문장을 sentences 리스트에 추가하고, 해당 문장만 새로 임베딩하여 embeddings 행렬에 수직으로 이어붙인다(vstack).
np.vstack([기존행렬, 새벡터]): 기존: (N, 768) + 새 벡터: (1, 768) → 결과: (N+1, 768) 이렇게 하면 전체를 재계산하지 않고 효율적으로 확장 가능. """ global embeddings # 전역 변수를 수정하므로 global 선언 필요
new_sentence = new_sentence.strip()
# ── 입력 유효성 검사 ───────────────────────────────────────── if not new_sentence: return get_sentence_list_md(), "⚠️ 문장을 입력해 주세요.", "" if new_sentence in sentences: return get_sentence_list_md(), "⚠️ 이미 존재하는 문장입니다.", ""
# ── 새 문장 임베딩 ─────────────────────────────────────────── # 기존 임베딩을 재활용하고 새 문장만 추가 인코딩 → 효율적 sentences.append(new_sentence) new_vec = model.encode([new_sentence], show_progress_bar=False) # shape: (1, 768) embeddings = np.vstack([embeddings, new_vec]) # shape: (N+1, 768)
return ( get_sentence_list_md(), # 갱신된 문장 리스트 표시 f"✅ 문장 추가 완료! (총 {len(sentences)}개)", # 상태 메시지 "", # 입력 필드 초기화 )
# ============================================================# 5. Gradio UI 정의# ============================================================# Gradio의 Blocks API:# - 컴포넌트(텍스트박스·버튼 등)를 자유롭게 배치# - .click() / .submit() 으로 Python 함수와 이벤트 연결# - inputs/outputs 는 gr.컴포넌트 객체로 지정
CSS = """body, .gradio-container { font-family: 'Noto Sans KR', 'Pretendard', sans-serif !important; background-color: #f8fafc !important; color: #111827 !important;}/* Gradio 내부 기본 회색 텍스트 전체 override */.gradio-container p,.gradio-container span,.gradio-container label,.gradio-container div,.gradio-container td,.gradio-container li { color: #111827 !important;}#app-header { background: linear-gradient(135deg, #1e3a5f 0%, #1d4ed8 60%, #2563eb 100%); border-radius: 16px; padding: 28px 36px; margin-bottom: 8px; text-align: center; box-shadow: 0 4px 20px rgba(37,99,235,0.25);}#app-header h1 { color: #ffffff !important; font-size: 2rem; font-weight: 800; margin: 0 0 6px 0; }#app-header p { color: #bfdbfe !important; font-size: 0.95rem; margin: 0; }#model-badge { display: inline-block; background: rgba(255,255,255,0.2); border: 1px solid rgba(255,255,255,0.5); color: #ffffff !important; border-radius: 20px; padding: 3px 14px; font-size: 0.8rem; margin-top: 10px;}.section-card { background: #ffffff; border: 1px solid #e2e8f0; border-radius: 12px; padding: 20px; box-shadow: 0 1px 6px rgba(0,0,0,0.07);}/* 섹션 제목: 진한 네이비 */.section-title { color: #1e3a8a !important; font-size: 1.05rem; font-weight: 800; margin-bottom: 12px; letter-spacing: -0.3px;}/* 마크다운 렌더링 영역 */.prose * { color: #111827 !important; }.prose h3 { color: #1e3a8a !important; font-weight: 800; }.prose table { width: 100%; border-collapse: collapse; }.prose table th { background: #dbeafe; color: #1e3a8a !important; padding: 9px 12px; border-bottom: 2px solid #93c5fd; font-weight: 800;}.prose table td { padding: 7px 12px; border-bottom: 1px solid #e2e8f0; color: #111827 !important; font-weight: 500;}.prose table td *,.prose table td p,.prose table td span { color: #111827 !important;}.prose table tr:hover td { background: #eff6ff; }/* 버튼: 파란색 계열로 통일 */button.primary, .gradio-container button[class*="primary"] { background: #1d4ed8 !important; border-color: #1d4ed8 !important; color: #ffffff !important;}button.primary:hover, .gradio-container button[class*="primary"]:hover { background: #1e40af !important; border-color: #1e40af !important;}"""
with gr.Blocks(css=CSS, title="벡터 검색 실습") as demo:
# ── 헤더 ────────────────────────────────────────────────────── gr.HTML(""" <div id="app-header"> <h1>🔎 벡터 검색 실습</h1> <p>한국어·다국어 문장을 벡터로 변환하고, 의미 기반 유사도 검색을 체험해보세요.</p> <span id="model-badge">Alibaba-NLP/gte-multilingual-base</span> </div> """)
# ── 2열 레이아웃 ─────────────────────────────────────────────── with gr.Row(equal_height=False):
# ── 왼쪽: 문장 리스트 ───────────────────────────────────── with gr.Column(scale=1, min_width=340): gr.HTML('<div class="section-title">📋 현재 문장 리스트</div>') # gr.Markdown: 마크다운 텍스트를 HTML로 렌더링하는 컴포넌트 # value를 함수로 업데이트하면 실시간으로 화면에 반영됨 sentence_list_md = gr.Markdown( value=get_sentence_list_md(), elem_classes=["prose"], )
# ── 오른쪽: 검색 + 문장 추가 ────────────────────────────── with gr.Column(scale=2):
# ① 검색 섹션 with gr.Group(elem_classes=["section-card"]): gr.HTML('<div class="section-title">🔍 의미 기반 검색 (Top 5)</div>') with gr.Row(): search_input = gr.Textbox( placeholder="검색할 문장을 입력하세요...", label="검색 입력", scale=4, show_label=False, ) search_btn = gr.Button("검색", variant="primary", scale=1) # 검색 결과가 여기에 마크다운 테이블로 표시됨 search_result_md = gr.Markdown( value="검색어를 입력하고 **검색** 버튼을 누르세요.", elem_classes=["prose"], )
gr.HTML("<br/>")
# ② 문장 추가 섹션 with gr.Group(elem_classes=["section-card"]): gr.HTML('<div class="section-title">➕ 문장 추가 (즉시 임베딩)</div>') with gr.Row(): add_input = gr.Textbox( placeholder="추가할 새 문장을 입력하세요...", label="새 문장", scale=4, show_label=False, ) add_btn = gr.Button("추가", variant="primary", scale=1) add_status = gr.Markdown(value="") # 추가 성공/실패 메시지 표시
# ============================================================ # 6. 이벤트 핸들러 연결 # ============================================================ # .click(fn, inputs, outputs): # - fn : 호출할 Python 함수 # - inputs : 함수 인자로 전달할 컴포넌트 리스트 # - outputs : 함수 반환값을 반영할 컴포넌트 리스트 # 반환값이 tuple이면 outputs 순서대로 각 컴포넌트에 매핑
# 검색 버튼 클릭 search_btn.click( fn=search_sentences, inputs=[search_input], outputs=[search_result_md, search_input], # (결과MD, 검색창초기화) ) # Enter 키로도 동일하게 검색 실행 search_input.submit( fn=search_sentences, inputs=[search_input], outputs=[search_result_md, search_input], )
# 문장 추가 버튼 클릭 add_btn.click( fn=add_sentence, inputs=[add_input], outputs=[sentence_list_md, add_status, add_input], # (리스트갱신, 상태메시지, 입력초기화) ) # Enter 키로도 동일하게 문장 추가 add_input.submit( fn=add_sentence, inputs=[add_input], outputs=[sentence_list_md, add_status, add_input], )
# ============================================================# 7. 앱 실행# ============================================================# inbrowser=True: 실행 시 브라우저 자동 오픈# share=True 를 추가하면 외부 공유 URL(Gradio 임시 서버) 생성 가능if __name__ == "__main__": demo.launch(inbrowser=True)해당 프로그램을 입력하고 난 후 터미널에서 다음 명령을 수행합니다.
D:\vector-search>python vector-search-app.py그러면 다음과 같은 화면을 볼 수 있습니다.
[Alibaba-NLP/gte-multilingual-base] 모델을 로드합니다...최초 실행 시 모델 다운로드로 인해 수 분이 소요될 수 있습니다.Some weights of the model checkpoint at Alibaba-NLP/gte-multilingual-base were not used when initializing NewModel: ['classifier.bias', 'classifier.weight']- This IS expected if you are initializing NewModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).- This IS NOT expected if you are initializing NewModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).모델 로드 완료!
E:\ai-test-project\vector-search\vector-search-app.py:278: UserWarning: The parameters have been moved from the Blocks constructor to the launch() method in Gradio 6.0: css. Please pass these parameters to launch() instead. with gr.Blocks(css=CSS, title="벡터 검색 실습") as demo:* Running on local URL: http://127.0.0.1:8000* To create a public link, set `share=True` in `launch()`.위 로그에 나오는 ” Running on local URL: http://127.0.0.1:8000” 에서 본인의 PC의 주소를 클릭해서 (Ctrl+click) 혹은 웹 브라우져를 띄운다음 해당 주소를 입력합니다.(예:http://127.0.0.1:8000 뒤에 : 다음에 나오는 포트번호는 각자 틀릴 수 있음. 터미널의 정보를 확인 한 후에 띄워주세요)
해당 브라우져로 실행을 하면 다음 화면을 확인할 수 있다.
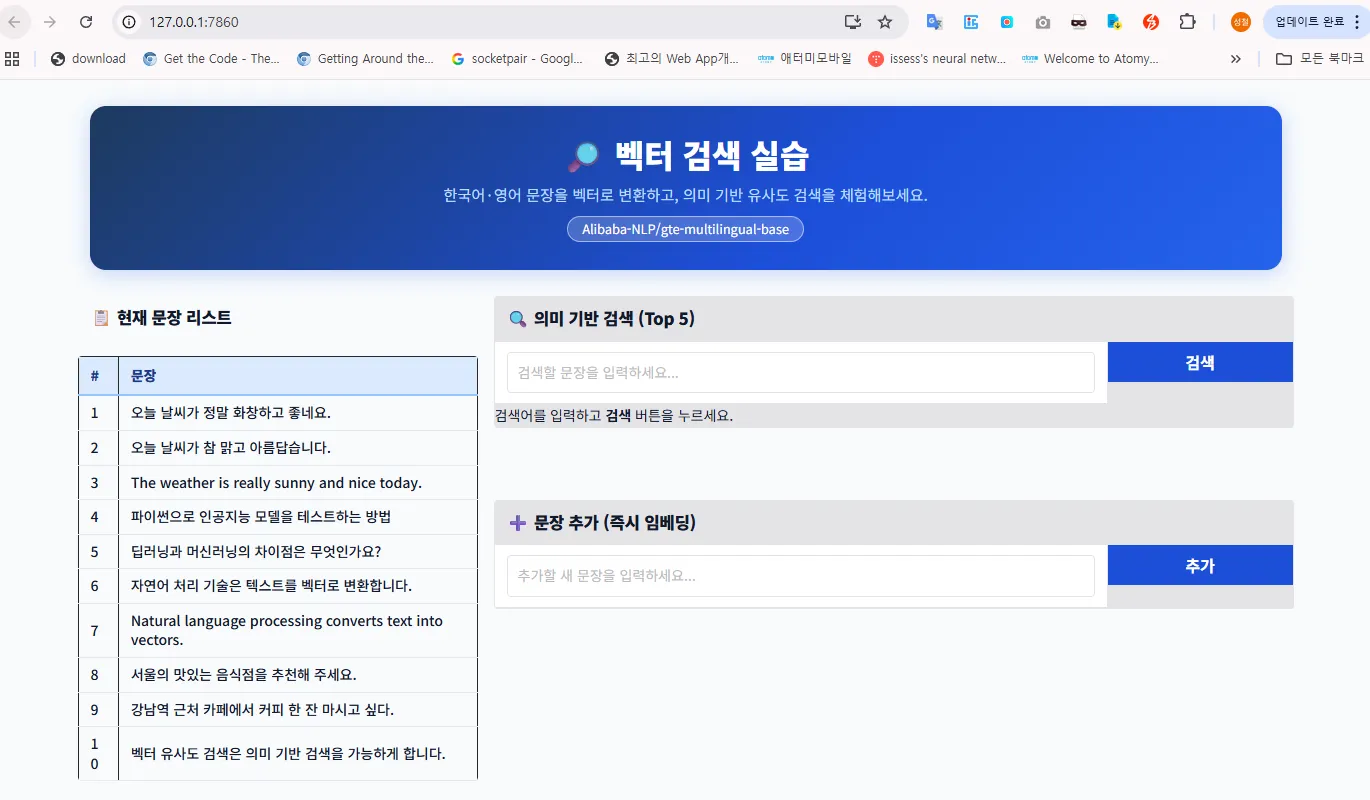
2. 참고 - 그라디오(Gradio) 소개
Section titled “2. 참고 - 그라디오(Gradio) 소개”그라디오(Gradio)란 무엇일까요?
Section titled “그라디오(Gradio)란 무엇일까요?”그라디오는 파이썬(Python) 코드 단 몇 줄만으로, 내가 만든 AI 모델을 테스트할 수 있는 번듯한 ‘웹 페이지 화면’을 뚝딱 만들어주는 마법 같은 라이브러리입니다.
보통 웹 페이지를 만들려면 HTML, CSS, 자바스크립트 등 복잡한 프론트엔드 웹 기술을 따로 배워야 합니다. 하지만 그라디오를 사용하면 파이썬 코드만으로 입력창, 버튼, 결과 출력창이 있는 깔끔한 UI(사용자 인터페이스)를 만들 수 있습니다.
💡 비유하자면:
여러분이 방금 임베딩 모델이라는 아주 훌륭한 **‘주방장’**을 고용했다고 해보겠습니다. 주방장만 있으면 손님을 받을 수 없죠? 손님에게 주문을 받고 요리를 내어줄 **‘드라이브스루 주문 창구’**가 필요한데, 그라디오가 바로 그 창구를 단 10초 만에 지어주는 역할을 합니다.
그라디오(Gradio)는 누가 만들었을까요? (제작 배경)
Section titled “그라디오(Gradio)는 누가 만들었을까요? (제작 배경)”-
출발과 인수 (Hugging Face의 핵심 도구): 그라디오는 원래 스탠포드 대학교 출신의 연구진들이 모여 만든 동명의 스타트업에서 처음 개발되었습니다. 이후 그 압도적인 편리함과 잠재력을 인정받아, 2021년 말에 전 세계 최대의 AI 오픈소스 플랫폼이자 커뮤니티인 **허깅페이스(Hugging Face)**에 공식적으로 인수되었습니다. 현재는 허깅페이스 생태계에서 모델을 시연할 때 사용하는 가장 표준적인 UI 도구로 자리 잡았습니다.
-
탄생 철학 (머신러닝의 민주화): 그라디오 제작진의 핵심 모토는 *“누구나 머신러닝 모델을 쉽게 테스트하고 공유할 수 있게 하자”*였습니다. 과거에는 데이터 과학자나 AI 연구원들이 기가 막힌 AI 모델을 만들어 놓고도, 프론트엔드(웹) 개발 지식이 없어서 사람들에게 보여주지 못하는 고충이 있었습니다. 그라디오는 바로 이 장벽을 허물고 **“파이썬 코드 몇 줄만으로 전 세계 누구에게나 내 AI를 자랑할 수 있게 하자”**는 목표로 탄생했습니다.
-
오픈소스의 힘: 완전한 무료 오픈소스 라이브러리입니다. 최신 AI 논문이 발표되거나 새로운 오픈소스 LLM이 공개될 때, 사람들이 해당 모델을 직접 써볼 수 있도록 제공되는 웹 데모 화면의 90% 이상이 바로 이 그라디오로 만들어져 있습니다.