02 임베딩을 이용한 유사도 벡터검색
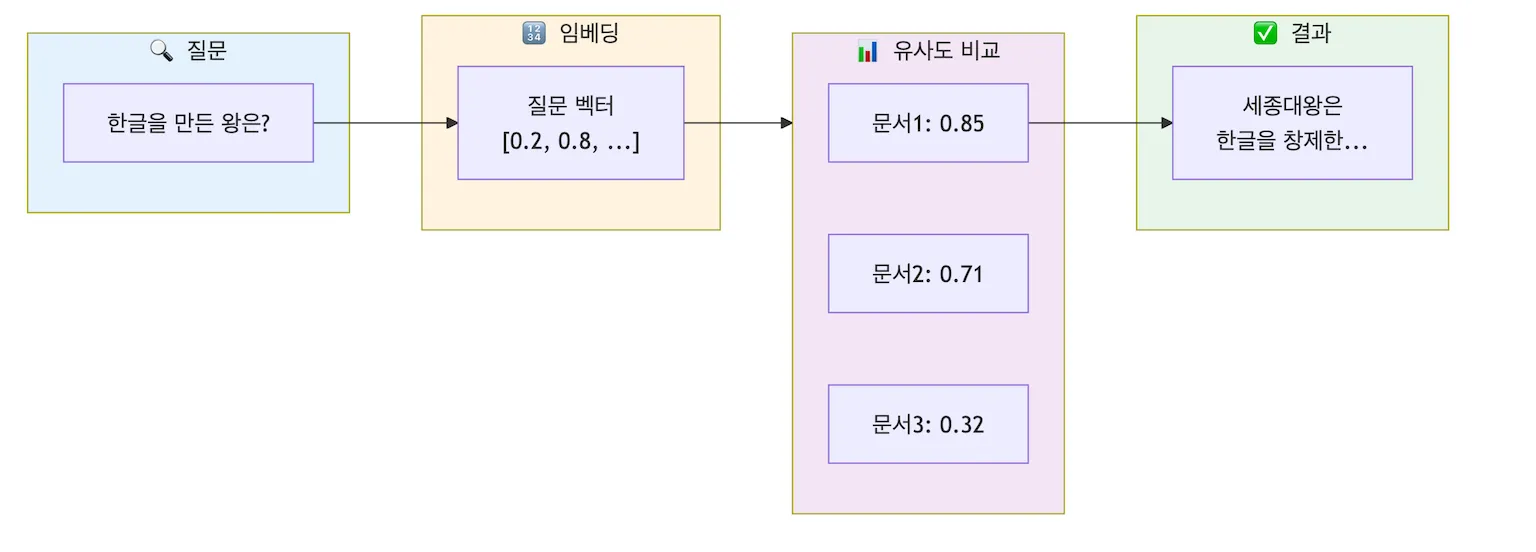
1. 임베딩이 끝났다면? “얼마나 비슷한가”를 잴 시간!
Section titled “1. 임베딩이 끝났다면? “얼마나 비슷한가”를 잴 시간!”임베딩 과정을 통해 단어나 문장을 기계가 계산할 수 있는 숫자들의 모음인 **‘벡터(Vector)‘**로 만들었습니다. 그렇다면 자연스럽게 다음 질문이 떠오릅니다. “A 문장과 B 문장은 의미가 얼마나 비슷할까?”
마치 지도 위에서 두 목적지 사이의 거리를 자로 재는 것처럼, 고차원의 벡터 공간 안에서 두 데이터가 얼마나 가깝고 비슷한지를 수학적으로 계산하여 점수로 나타내는 것을 **‘유사도(Similarity) 측정’**이라고 합니다.
2. 코사인 유사도(Cosine Similarity): “방향”을 비교하다
Section titled “2. 코사인 유사도(Cosine Similarity): “방향”을 비교하다”자연어 처리(NLP) 분야를 비롯하여 텍스트를 분석할 때 가장 대중적으로 사용되는 기준이 바로 **‘코사인 유사도(Cosine Similarity)‘**입니다.
이름에 ‘코사인’이라는 수학 용어가 들어가서 복잡해 보이지만, 핵심 아이디어는 아주 단순합니다. 벡터의 ‘길이(문서의 길이나 단어의 빈도)‘는 무시하고, 두 벡터(화살표)가 가리키는 “방향”이 얼마나 비슷한지만을 집중적으로 측정하는 것입니다.
💡 직관적 이해: 화살표 두 개를 상상해 보세요!
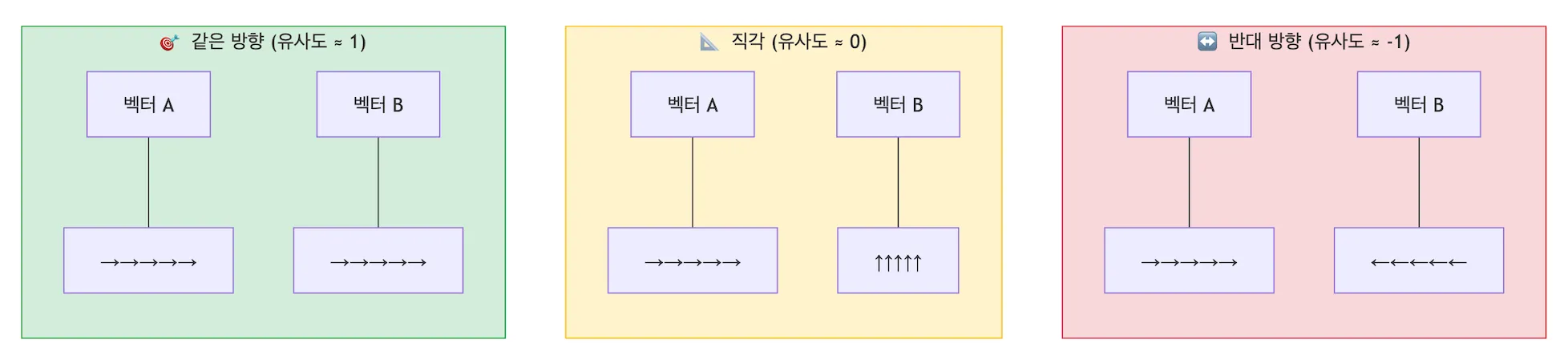
Section titled “💡 직관적 이해: 화살표 두 개를 상상해 보세요!”임베딩된 단어 벡터를 허공에 떠 있는 ‘화살표’라고 상상해 보겠습니다. 두 화살표 사이의 벌어진 각도에 따라 유사도는 1점에서 -1점 사이의 값으로 깔끔하게 떨어집니다.
-
1점 (완전 동일 / 0도): ➔ ➔
두 화살표가 완벽하게 같은 방향을 가리킵니다. 두 단어나 문장의 의미가 완벽하게 똑같거나 매우 유사하다는 뜻입니다.
-
0점 (관련 없음 / 90도): ➔ ⬆
두 화살표가 교차로처럼 직각을 이룹니다. 두 단어 사이에 아무런 연관성이나 공통된 문맥이 없음을 의미합니다.
-
-1점 (완전 반대 / 180도): ➔ ⬅
두 화살표가 완전히 반대 방향으로 등을 지고 있습니다. 두 단어의 의미가 정반대(대척점)에 있다는 뜻입니다. (예: 기쁨과 슬픔)
3. 코사인 유사도의 실제 수학 공식
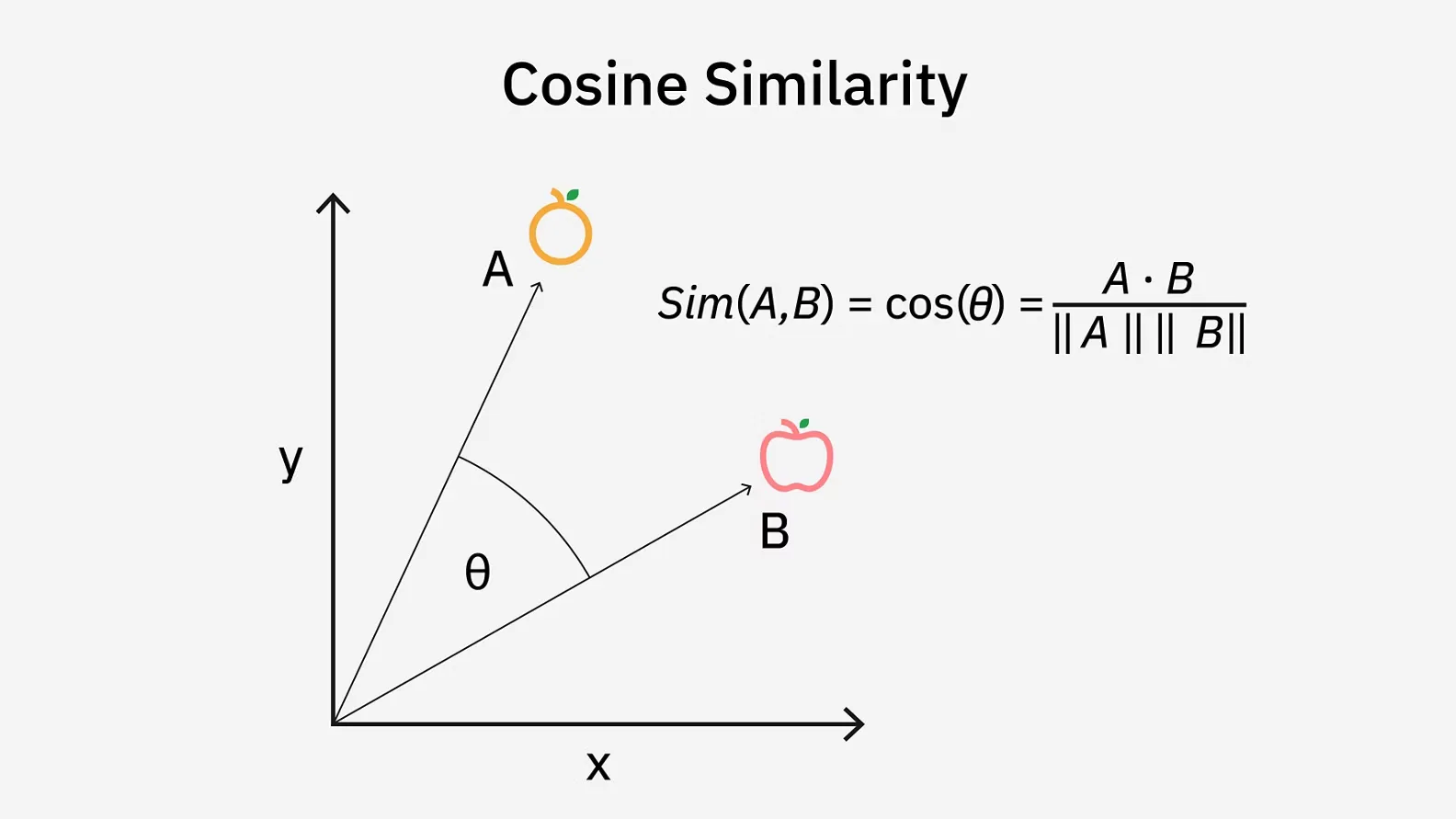
Section titled “3. 코사인 유사도의 실제 수학 공식”그렇다면 컴퓨터는 이 화살표의 방향(각도)을 어떻게 계산할까요? 실제 수식은 다음과 같습니다.
$$\text{Cosine Similarity}(\mathbf{A}, \mathbf{B}) = \frac{\mathbf{A} \cdot \mathbf{B}}{|\mathbf{A}| |\mathbf{B}|} = \frac{\sum_{i=1}^{n} A_i B_i}{\sqrt{\sum_{i=1}^{n} A_i^2} \sqrt{\sum_{i=1}^{n} B_i^2}}$$
수식이 길어 보이지만, 위(분자)와 아래(분모) 두 부분으로 나누어 보면 그 원리가 아주 명쾌합니다.
-
분자 ($\mathbf{A} \cdot \mathbf{B}$): 두 벡터의 내적 (Dot Product)
- 각 위치에 있는 숫자끼리 곱한 뒤 모두 더한 값입니다. 두 벡터가 비슷한 방향을 향할수록 이 값은 커집니다.(예: 2차원일때 수식 $$\vec{a}\cdot\vec{b}=x_1x_2+y_1y_2$$)
-
분모 ($|\mathbf{A}| |\mathbf{B}|$): 두 벡터의 크기(길이)의 곱
- 각 벡터가 가진 순수한 ‘길이’를 구해서 곱한 값입니다.
-
핵심 원리 (정규화):
-
분자(내적) 값 자체는 벡터의 길이에 영향을 받습니다. 문서가 길어서 단어가 많이 등장하면 값도 커지게 되죠.
-
그래서 이 값을 분모(벡터의 길이)로 나누어 줍니다. 이렇게 하면 순수하게 ‘길이’의 영향력은 사라지고, 오직 ‘방향(각도)‘에 대한 정보만 남게 됩니다. ---
-
2차원일때 수식 $$\vec{a}\cdot\vec{b}=|\vec{a}||\vec{b}|\cos\theta$$
-
4. 왜 하필 ‘코사인 유사도’를 가장 많이 쓸까요?
Section titled “4. 왜 하필 ‘코사인 유사도’를 가장 많이 쓸까요?”LLM이나 RAG(검색 증강 생성) 시스템을 구축할 때, 벡터 데이터베이스에서 가장 유사한 문서를 찾기 위한 기본 설정은 대부분 ‘코사인 유사도’입니다. 그 이유는 텍스트 데이터가 가진 고유한 특징 때문입니다.
① 문서의 ‘길이’에 영향을 받지 않습니다.
예를 들어 ‘사과’라는 단어가 10번 들어간 짧은 블로그 글(A)과, 100번 들어간 아주 긴 백과사전 글(B)이 있다고 해보겠습니다. 두 글은 길이가 크게 다르지만, 주제는 ‘사과’로 같습니다.
코사인 유사도는 벡터의 길이를 무시하고 방향만 보기 때문에, 짧은 문서와 긴 문서의 주제(의미)가 같다면 아주 높은 유사도 점수를 줍니다. 텍스트 분석에서는 이것이 매우 중요합니다.
② 고차원 공간에서 계산이 효율적입니다.
우리가 사용하는 임베딩 벡터는 적게는 수백에서 많게는 수천 차원(예: 768차원, 1536차원 등)을 가집니다. 이렇게 차원이 무한히 넓은 공간에서는 일반적인 거리 계산법이 제 기능을 못 하는 경우가 많은데, 코사인 유사도는 각도만을 계산하므로 고차원에서도 안정적이고 빠르게 동작합니다.
5. 코사인 유사도 외의 다른 측정 방법들 (참고만 하세요)
Section titled “5. 코사인 유사도 외의 다른 측정 방법들 (참고만 하세요)”물론 코사인 유사도만 있는 것은 아닙니다. 상황과 목적에 따라 다음과 같은 다른 유사도 지표들을 사용하기도 합니다.
5.1. 유클리드 거리 (Euclidean Distance)
Section titled “5.1. 유클리드 거리 (Euclidean Distance)”-
개념: 우리가 흔히 아는 물리적인 직선거리를 재는 방법입니다. (피타고라스의 정리를 생각하시면 됩니다.) 벡터 공간에서 두 점 사이의 실제 거리를 잽니다.
-
특징: 값이 작을수록(거리가 짧을수록) 유사하다는 뜻입니다.
-
한계: 앞서 말한 ‘사과’ 문서 예시처럼, 주제가 같아도 문서의 길이가 다르면 두 점 사이의 거리가 멀어지기 때문에 유사도가 낮게 측정되는 치명적인 단점이 있습니다. 텍스트보다는 이미지나 수치 데이터를 비교할 때 자주 쓰입니다.
5.2. 내적 (Dot Product)
Section titled “5.2. 내적 (Dot Product)”- 개념: 코사인 유사도 공식의 ‘분자’ 부분만 계산하는 방법입니다.
- 특징: 방향이 얼마나 비슷한지도 고려하지만, 벡터의 길이(문서의 길이나 정보량)도 함께 고려합니다. 즉, 주제도 비슷하면서 문서의 내용(단어 출현 빈도)도 풍부한 것을 더 높은 점수로 쳐주고 싶을 때 사용합니다.
5.3. 자카드 유사도 (Jaccard Similarity)
Section titled “5.3. 자카드 유사도 (Jaccard Similarity)”- 개념: 두 문장을 ‘단어의 집합’으로 보고, 전체 단어 중에서 겹치는 단어의 비율을 계산하는 방법입니다.
- 특징: 교집합을 합집합으로 나눈 값입니다. 벡터 공간의 기하학적 계산보다는, “이 문서와 저 문서에 똑같은 단어가 얼마나 자주 등장했나?”를 아주 단순하고 직관적으로 파악할 때 유용합니다. 하지만 단어의 ‘숨은 의미’를 파악하지는 못합니다.