00 사전 준비사항
파이썬 버전 확인(중요) 및 사전 패키지 설치
Section titled “파이썬 버전 확인(중요) 및 사전 패키지 설치”- 파이썬 버전*이 현재 해당 모델과 호환되는 것이(대부분 LLM 사용시) 3.10 / 3.12가 문제 없이 호환이 됩니다. 이 부분 체크해서 만약 3.14버전인경우 3.12를 설치하여 사용해주세요.
- 버전 확인(python —version)
- https://www.python.org/ftp/python/3.12.10/python-3.12.10-amd64.exe
- 여러 버전 사용이 필요한 경우 가상 환경 생성으로 사요해야 됨(Python 가상환경 사용 참고)
- 현재 실습 관련 라이브러리 설치 파일 (requirement.txt 생성)
- pip install -r requirements.txt 로 실습환경과 동일한 라이브러리 설치
google-genai==1.61.0chromadb==1.4.1sentence-transformers==5.2.2torch==2.6.0transformers==4.57.6gradio==6.5.1numpy==2.1.3python-dotenv==1.2.1- 가상환경 사용시(여러버전 사용시에) 설치 예# 1. Python 3.12 가상환경 생성 & 활성화(런처 사용시)py -3.12 -m venv venv # Windowsvenv\Scripts\activate # Windows CMD
# 2. 패키지 설치pip install -r requirements.txtpython vector-model-test.py모델 사전 다운로드 준비
Section titled “모델 사전 다운로드 준비”이번에 임베딩 모델에 대해서 실습을 하기 위해서 실제 사용되는 모델을 다운로드를 해야 합니다. 해당 모델이 약 611MB이기 때문에 교육에 앞서 미리 다운로드 합니다.
해당 코드 실행 후 파이썬에서 해당 모델을 개인 영역의 파이썬 캐시에 미리 다운로드가 됩니다.
먼저 실습할 디렉토리를 만듭니다.(vector-search)
Antigravity에서 해당 디렉토리를 열고(빈 프로젝트) 상단메뉴의 “Terminal”의 “New Terminal”을 누릅니다. 그러면 하단에 터미널 창이 나타납니다.
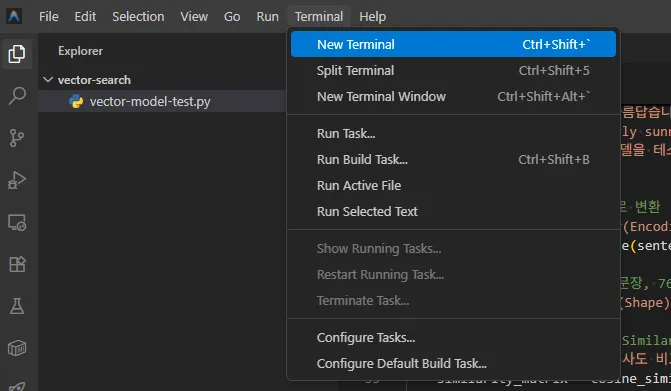 그리고 다음 명령을 수행합니다.(Antigravity에서 해당 )
기존에 Python이 정상적으로 설치되어 있는 상태라면 해당 패키지가 정상으로 설치될것입니다.
그리고 다음 명령을 수행합니다.(Antigravity에서 해당 )
기존에 Python이 정상적으로 설치되어 있는 상태라면 해당 패키지가 정상으로 설치될것입니다.
D:\vector-search>pip install sentence-transformers scikit-learn그리고 비어있는 파일을 생성합니다. 파일이름은 vector-model-test.py로 합니다. 해당 피어있는 파일에 다음 코드를 복사 붙여 넣기 합니다.
# 사전 설치 : pip install sentence-transformers scikit-learn
import osfrom sentence_transformers import SentenceTransformerfrom sklearn.metrics.pairwise import cosine_similarity
def main(): model_id = "Alibaba-NLP/gte-multilingual-base"
# 1. 모델 로드 (최초 실행 시 자동으로 캐시에 다운로드됨) print(f"[{model_id}] 모델을 로드합니다.") print("최초 실행 시 허깅페이스 캐시 폴더로 모델을 다운로드하므로 시간이 약간 소요됩니다...")
# trust_remote_code=True 가 필요한 모델일 경우를 대비해 추가 인자를 넣는 것이 좋습니다. model = SentenceTransformer(model_id, trust_remote_code=True) print("모델 로드 완료!\n")
# 2. 벡터로 변환할 테스트 문장 리스트 sentences = [ "오늘 날씨가 정말 화창하고 좋네요.", # 0. 한국어 "오늘 날씨가 참 맑고 아름답습니다.", # 1. 한국어 (0번과 의미 비슷) "The weather is really sunny and nice today.", # 2. 영어 (0번과 의미 동일) "파이썬으로 인공지능 모델을 테스트하는 방법", # 3. 전혀 다른 의미의 문장 ]
# 3. 텍스트를 벡터(임베딩)로 변환 print("문장들을 벡터로 변환(Encoding) 중...") embeddings = model.encode(sentences)
# 벡터 형태 확인 (예: 4개 문장, 768 차원) print(f"생성된 벡터의 형태(Shape): {embeddings.shape}\n")
# 4. 코사인 유사도(Cosine Similarity)를 통한 테스트 결과 확인 print("=== 문장 간 의미 유사도 비교 ===") similarity_matrix = cosine_similarity(embeddings)
# 0번 문장을 기준으로 다른 문장들과의 유사도 비교 base_idx = 0 base_sentence = sentences[base_idx]
for i in range(1, len(sentences)): target_sentence = sentences[i] score = similarity_matrix[base_idx][i] print(f"기준 문장: '{base_sentence}'") print(f"비교 문장: '{target_sentence}'") print(f"-> 유사도 점수: {score:.4f}\n")
if __name__ == "__main__": main()해당 코드를 붙여넣었으면 Ctrl+S 로 저장을 하고 Command 창에서 다음을 실행합니다.
D:\vector-search>python vector-model-test.py그러면 다음과 같은 화면이 나타나면서 해당 임베딩 모델을 다운로드 합니다. 다음과 같이 모델을 다운로드 한 다음에 테스트가 되면 성공입니다.
$ python vector-model-test.py[Alibaba-NLP/gte-multilingual-base] 모델을 로드합니다.최초 실행 시 허깅페이스 캐시 폴더로 모델을 다운로드하므로 시간이 약간 소요됩니다...modules.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████| 349/349 [00:00<?, ?B/s]C:\Python312\Lib\site-packages\huggingface_hub\file_download.py:143: UserWarning: `huggingface_hub` cache-system uses symlinks by default to efficiently store duplicated files but your machine does not support them in C:\Users\User\.cache\huggingface\hub\models--Alibaba-NLP--gte-multilingual-base. Caching files will still work but in a degraded version that might require more space on your disk. This warning can be disabled by setting the `HF_HUB_DISABLE_SYMLINKS_WARNING` environment variable. For more details, see https://huggingface.co/docs/huggingface_hub/how-to-cache#limitations.To support symlinks on Windows, you either need to activate Developer Mode or to run Python as an administrator. In order to activate developer mode, see this article: https://docs.microsoft.com/en-us/windows/apps/get-started/enable-your-device-for-development warnings.warn(message)README.md: 124kB [00:00, 40.7MB/s]sentence_bert_config.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████| 55.0/55.0 [00:00<?, ?B/s]config.json: 1.43kB [00:00, ?B/s]configuration.py: 7.13kB [00:00, ?B/s]C:\Python312\Lib\site-packages\huggingface_hub\file_download.py:143: UserWarning: `huggingface_hub` cache-system uses symlinks by default to efficiently store duplicated files but your machine does not support them in C:\Users\User\.cache\huggingface\hub\models--Alibaba-NLP--new-impl. Caching files will still work but in a degraded version that might require more space on your disk. This warning can be disabled by setting the `HF_HUB_DISABLE_SYMLINKS_WARNING` environment variable. For more details, see https://huggingface.co/docs/huggingface_hub/how-to-cache#limitations.To support symlinks on Windows, you either need to activate Developer Mode or to run Python as an administrator. In order to activate developer mode, see this article: https://docs.microsoft.com/en-us/windows/apps/get-started/enable-your-device-for-development warnings.warn(message)A new version of the following files was downloaded from https://huggingface.co/Alibaba-NLP/new-impl:- configuration.py. Make sure to double-check they do not contain any added malicious code. To avoid downloading new versions of the code file, you can pin a revision.modeling.py: 59.0kB [00:00, 39.2MB/s]A new version of the following files was downloaded from https://huggingface.co/Alibaba-NLP/new-impl:- modeling.py. Make sure to double-check they do not contain any added malicious code. To avoid downloading new versions of the code file, you can pin a revision.Xet Storage is enabled for this repo, but the 'hf_xet' package is not installed. Falling back to regular HTTP download. For better performance, install the package with: `pip install huggingface_hub[hf_xet]` or `pip install hf_xet`model.safetensors: 100%|████████████████████████████████████████████████████████████████████████████████████████████| 611M/611M [01:54<00:00, 5.33MB/s]Some weights of the model checkpoint at Alibaba-NLP/gte-multilingual-base were not used when initializing NewModel: ['classifier.bias', 'classifier.weight']- This IS expected if you are initializing NewModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).- This IS NOT expected if you are initializing NewModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).tokenizer_config.json: 1.15kB [00:00, ?B/s]Xet Storage is enabled for this repo, but the 'hf_xet' package is not installed. Falling back to regular HTTP download. For better performance, install the package with: `pip install huggingface_hub[hf_xet]` or `pip install hf_xet`tokenizer.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████| 17.1M/17.1M [00:02<00:00, 5.73MB/s]special_tokens_map.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████| 964/964 [00:00<?, ?B/s]config.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████| 190/190 [00:00<?, ?B/s]모델 로드 완료!
문장들을 벡터로 변환(Encoding) 중...생성된 벡터의 형태(Shape): (4, 768)
=== 문장 간 의미 유사도 비교 ===기준 문장: '오늘 날씨가 정말 화창하고 좋네요.'비교 문장: '오늘 날씨가 참 맑고 아름답습니다.'-> 유사도 점수: 0.8310
기준 문장: '오늘 날씨가 정말 화창하고 좋네요.'비교 문장: 'The weather is really sunny and nice today.'-> 유사도 점수: 0.8241
기준 문장: '오늘 날씨가 정말 화창하고 좋네요.'비교 문장: '파이썬으로 인공지능 모델을 테스트하는 방법'-> 유사도 점수: 0.2607- 자연어로 쇼핑 어시스턴트를 개발합니다.
오류 발생시 참고
Section titled “오류 발생시 참고”다음 오류시(버전 충돌) 재설치
(venv) C:\vector-search>python vector-model-test.py[Alibaba-NLP/gte-multilingual-base] 모델을 로드합니다.최초 실행 시 허깅페이스 캐시 폴더로 모델을 다운로드하므로 시간이 약간 소요됩니다...Warning: You are sending unauthenticated requests to the HF Hub. Please set a HF_TOKEN to enable higher rate limits and faster downloads.Loading weights: 100%|█████████████████████████████████████████████████████████████| 136/136 [00:00<00:00, 5346.22it/s]NewModel LOAD REPORT from: Alibaba-NLP/gte-multilingual-baseKey | Status | |------------------+------------+--+-classifier.bias | UNEXPECTED | |classifier.weight | UNEXPECTED | |
Notes:- UNEXPECTED: can be ignored when loading from different task/architecture; not ok if you expect identical arch.모델 로드 완료!
문장들을 벡터로 변환(Encoding) 중...Traceback (most recent call last): File "C:\vector-search\vector-model-test.py", line 49, in <module> main() File "C:\vector-search\vector-model-test.py", line 28, in main embeddings = model.encode(sentences) ^^^^^^^^^^^^^^^^^^^^^^^ File "C:\vector-search\venv\Lib\site-packages\torch\utils\_contextlib.py", line 124, in decorate_context return func(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^ File "C:\vector-search\venv\Lib\site-packages\sentence_transformers\SentenceTransformer.py", line 1094, in encode out_features = self.forward(features, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\vector-search\venv\Lib\site-packages\sentence_transformers\SentenceTransformer.py", line 1175, in forward input = module(input, **module_kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\vector-search\venv\Lib\site-packages\torch\nn\modules\module.py", line 1779, in _wrapped_call_impl return self._call_impl(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\vector-search\venv\Lib\site-packages\torch\nn\modules\module.py", line 1790, in _call_impl return forward_call(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\vector-search\venv\Lib\site-packages\sentence_transformers\models\Transformer.py", line 262, in forward outputs = self.auto_model(**trans_features, **kwargs, return_dict=True) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\vector-search\venv\Lib\site-packages\torch\nn\modules\module.py", line 1779, in _wrapped_call_impl return self._call_impl(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\vector-search\venv\Lib\site-packages\torch\nn\modules\module.py", line 1790, in _call_impl return forward_call(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\user\.cache\huggingface\modules\transformers_modules\Alibaba_hyphen_NLP\new_hyphen_impl\40ced75c3017eb27626c9d4ea981bde21a2662f4\modeling.py", line 901, in forward (embedding_output, attention_mask, rope_embeds, length) = self.embeddings( ^^^^^^^^^^^^^^^^ File "C:\vector-search\venv\Lib\site-packages\torch\nn\modules\module.py", line 1779, in _wrapped_call_impl return self._call_impl(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\vector-search\venv\Lib\site-packages\torch\nn\modules\module.py", line 1790, in _call_impl return forward_call(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\user\.cache\huggingface\modules\transformers_modules\Alibaba_hyphen_NLP\new_hyphen_impl\40ced75c3017eb27626c9d4ea981bde21a2662f4\modeling.py", line 392, in forward rope_cos = rope_cos[position_ids].unsqueeze(2) # [bs, seq_len, 1, dim] ~~~~~~~~^^^^^^^^^^^^^^IndexError: index 5542722600960 is out of bounds for dimension 0 with size 13
(venv) C:\vector-search>- 먼저 3.12를 설치하고 기존 버전을 삭제합니다.(venv 사용하기 힘든경우)*
- 그리고 version이 3.12가 맞는지 다시 확인합니다.(python —version)
# 모델 가중치 캐시 삭제rmdir /s /q "%USERPROFILE%\.cache\huggingface\hub\models--Alibaba-NLP--gte-multilingual-base"
# 커스텀 코드 캐시 삭제rmdir /s /q "%USERPROFILE%\.cache\huggingface\modules\transformers_modules\Alibaba_hyphen_NLP"
# torch + transformers 재설치pip install torch==2.6.0 transformers==4.57.6
# 3. 다시 패키지 설치 및 실행(모델 다시 다운로드)pip install -r requirements.txtpip install sentence-transformers scikit-learn
python vector-model-test.py